Before I worked on 4 Day Week, I worked as a Data Scientist for ~10 years (the job role that builds AI models, such as ChatGPT and DALLE) doing machine learning at companies like Microsoft, Yahoo and Solarwinds.
These days, some AI engineers are earning $400k+ or more (which is absolutely crazy!). So, how do you start a career in AI?
Well, here's my 10-step actionable guide to start your career in Data Science (no experience needed):
1. Learn Python
You'll need some coding skills as a data scientist - more than a data analyst but less than a software engineer. If you've never coded before, it can be intimidating... but here's the nice thing:
You only need to learn Python as (almost) all data science = Python. And what's even better? Python is one of the easiest languages to learn as a newbie.
Python is used for loading and transforming data and creating AI prediction models (we'll get to these later...). It's the data science language that does it all ✨

If you are starting, I recommend the Python for Data Science and Machine Learning Bootcamp, ideal for beginners and advanced learners alike. The course begins with Python basics and gradually moves into more complex areas like data manipulation and visualization.
2. Learn SQL
SQL (pronounced "sequel" or "ess-que-ell") is the technology used to work with databases. As a data scientist, you're going to work with a lot of data - so SQL knowledge is very useful (but not 100% necessary).
SQL allows you to load and sift through vast amounts of data to uncover essential insights, organize data efficiently, find the mix/max/average/whatever, and perform complex queries to determine trends and patterns. It provides the tools to manage and manipulate data systematically and effectively.
To learn SQL, I'd recommend doing the Complete SQL Bootcamp on Udemy. This course will take you from zero to one... and beyond!
3. Learn Statistics
Data Science is the intersection of programming and statistics (and economics - kinda).
My background was in Computer Science, so Statistics was my weak point. So here's my secret guide to learning statistics: YouTube! 😅
Statistics Crash Course was the YouTube course I took—and I highly recommend it! It's 50% learning and 50% entertainment. It makes a slightly dull topic (sorry Statisticians...) very interesting!
4. Build Your First Regression Model
I hear ya... "what is this regression model you speak of?" Well... you'll find out soon, but the tl;dr is:
A model is just something that simulates a real-world scenario in code.
A regression model is a specific type of model that takes input data (i.e., of numbers) and predicts a number - a single number.
For example, a student exam score regression model could take a University student's attendance rate, travel distance and study hours and attempt to predict their exam score.




Ready to find your 4-day week job?
Browse opportunities at companies that prioritize work-life balance.
Browse JobsThis YouTube playlist explains what a regression model is much better than I could.
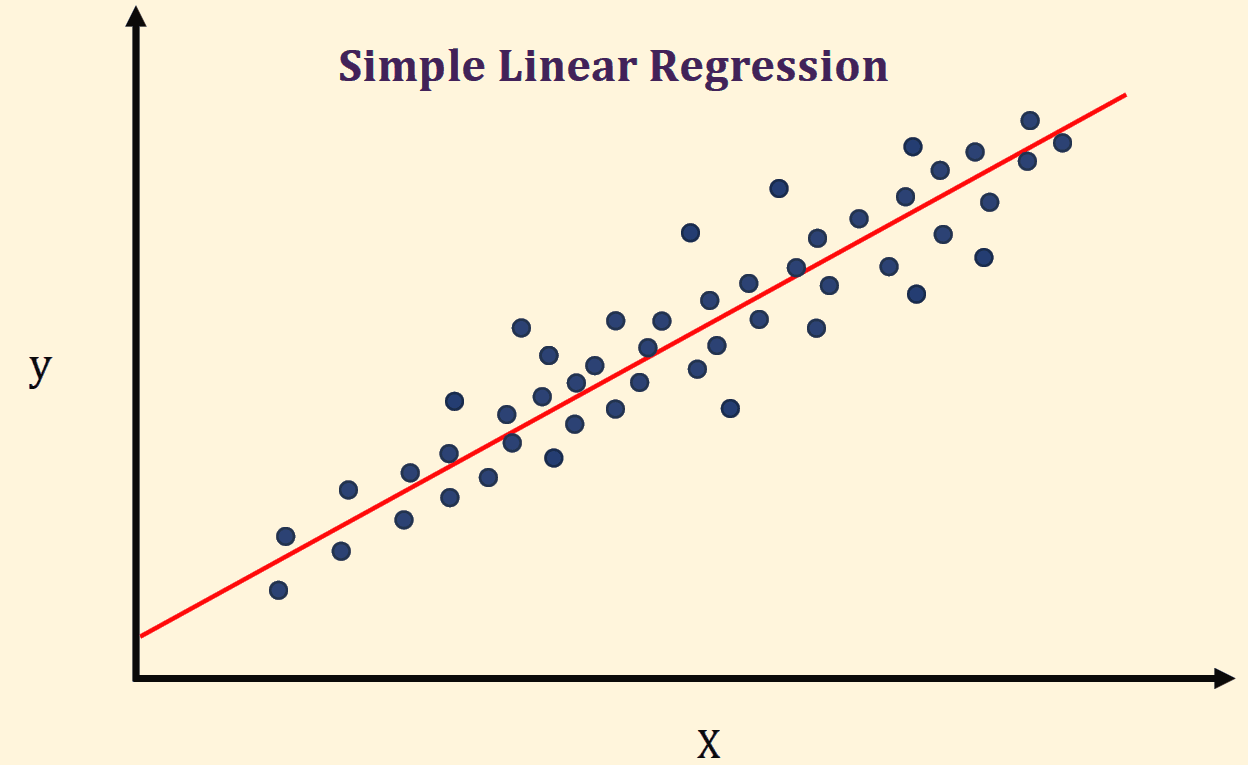
In its simplest form, linear regression is the process of finding a straight line that fits the dataset "best".
Once you know some Python and understand regression, you could build a regression model using Pandas + scikit-learn—these are two of the most popular Python packages for data scientists.
To get started on your first project, why not download this dataset from Kaggle (oh, you're going to spend a lot of time on Kaggle, by the way...) and attempt to predict a student's grade based on how many hours they studied?
5. Build Your First Classifier
Where regression predicts a number... classifiers predict a class (often just "yes" or "no"). Regression and classification are two of the main pillar-stones of machine learning - you'll need to be comfortable building both models.
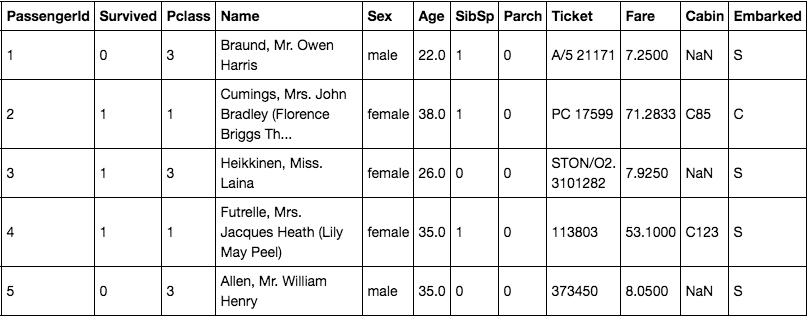
A common 1st classifier to build is where you attempt to predict if someone survived or died on the Titanic - gruesome I know... You'll also find this dataset on Kaggle.
6. Learn Deep Learning
Simple models such as linear regression are known as "shallow models". They are fast, easy to understand and typically "good enough" for most situations.
Deep learning, on the other hand, are much more complex and can handle much more complicated tasks (such as detecting objects in images). These models need more power and more data to learn from, but they can find patterns and details that shallow models might miss.
The current hype cycle of AI is all about "deep learning" and it's important to learn about it... but here's my advice to you:
Only use the simple models first (e.g. linear regression). Don't even Google "pytorch" until you can recite linear regression in your sleep. In every machine learning task you face: start simple (e.g. linear regression) and build your way up (e.g. other models such as xgboost, then deep neural networks).
I've never regretted starting with shallow models when building machine learning models - but I've often regretted starting with deep models. They are really complex, difficult to understand, and are almost always overkill.
That isn't to say they aren't good - they are incredible. But should only be used in certain situations (e.g. when you have millions of rows of input data).
A great course to get started with is a Deep Understanding of Deep Learning on Udemy - it starts with foundational concepts and gradually works its way up.
Get 4-day week jobs in your inbox
Create a free account to receive curated opportunities weekly.
Sign up for freeFree forever. No spam, unsubscribe anytime.
7. Build More Models & Pet Projects
Theory is important, but the real learning happens when you apply your knowledge.
The best way to learn (anything) is to do.
The more models you build, the better you understand the nuances of how algorithms work and how data behaves in different scenarios.
So go to Kaggle, download some data and build some models! p.s. it's pretty fun.
8. Get Some Certifications
Applying to data scientist jobs won't be easy without a degree in CompSci, Stats, Maths or Economics - I'm just being honest. So the next best thing would be to get some online certifications e.g. Amazon Machine Learning Certification ($300) or others (Google, Microsoft, IBM etc)
Certifications can significantly boost your credibility and show potential employers that you are serious about your craft.

9. Resume Optimization
Learning data science is just the beginning. The real work begins when you start applying for jobs - competing with 100's of others.
So to give yourself the best chance, your resume needs to be perfect - it needs to grab the attention of the recruiter. And how do you grab their attention? You should:
- Make your resume ATS-compliant to pass through the initial screening processes.
- Make each resume job specific (e.g. match the keywords in the job description with your resume)
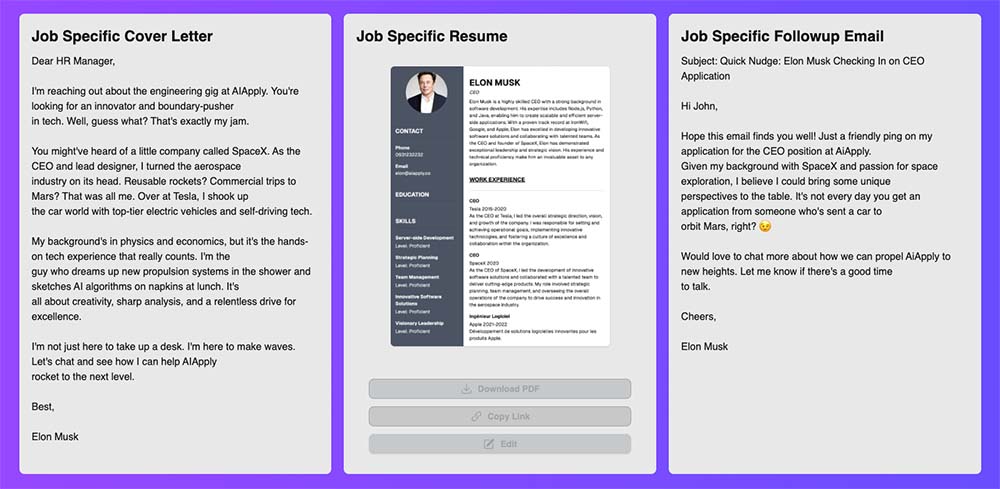
Tools like AiApply make this process much easier (see below).
10. Start Applying
Initially, I'd recommend apply to data analyst roles as they often require less experience and can serve as a stepping stone to more advanced positions.
A data analyst does all the the stuff a data scientist does, except the machine learning. Data Analyst roles are therefore easier to get - either that or "junior data scientist".
With persistence, continued learning, and practical application, you can chart a successful path in the ever-evolving field of data science.
Wishing you all the best in your journey to becoming a self-taught data scientist! 🤝


